【Python】datetime モジュールで日付や時間を扱えるようになろう!
まえがき
先日Pythonで日付ごとのデータを扱いたい場面があり、その際に学習したことをブログで共有したいと思います!
Pythonで日付や時間を扱う!
Pythonで日付を扱うにはdatetime型を使いましょう。
from datetime import datetime, timedelta
年月日を指定することでdatetime型の変数を作成できます。
today = datetime(2022, 3, 15) today ## Out ## ---- datetime.datetime(2022, 3, 15, 0, 0)
年月日より小さい単位も指定可能です。 時分秒も指定してみましょう。
day1 = datetime(2022, 3, 15, 17, 23, 40) day1 ## Out ## --- datetime.datetime(2022, 3, 15, 17, 23, 40)
print(day1) ## Out ## --- 2022-03-15 17:23:40
datetime型で足し算をする!
datetime型を使うメリットの1つとして日時の足し引き算といった計算が簡単にできることがあります。
日単位以下の差分計算
日時の差分を表現するには timedelta を使用します。
ただし、timedelta はdays以下の差分しか表現できません。(weeksも使えます)
# 足し算(days以下) print('当日:', day1) print('1日後:', day1+ timedelta(days=1)) print('1時間後:', day1+ timedelta(hours=1)) print('1分後:', day1+ timedelta(minutes=1)) print('1秒後:', day1+ timedelta(seconds=1)) ## Out ## --- 当日: 2022-03-15 17:23:40 1日後: 2022-03-16 17:23:40 1時間後: 2022-03-15 18:23:40 1分後: 2022-03-15 17:24:40 1秒後: 2022-03-15 17:23:41
weeksも使えます。
# weeksでも指定可能 print('当日:', day1) print('1週間:', day1+ timedelta(weeks=1)) ## Out ## --- 当日: 2022-03-15 17:23:40 1週間: 2022-03-22 17:23:40
月単位以上の差分計算
月単位以上の差分を表現するには relativedelta を使用しましょう。
from dateutil.relativedelta import relativedelta
# 足し算(months以上) print('当日:', day1) print('1ヶ月後:', day1+ relativedelta(months=1)) print('1年後:', day1+ relativedelta(years=1)) ## Out ## --- 当日: 2022-03-15 17:23:40 1ヶ月後: 2022-04-15 17:23:40 1年後: 2023-03-15 17:23:40
実はrelativedeltaは日単位以下も扱えます。
# 足し算(days以下) print('当日:', day1) print('1日後:', day1+ relativedelta(days=1)) print('1時間後:', day1+ relativedelta(hours=1)) print('1分後:', day1+ relativedelta(minutes=1)) print('1秒後:', day1+ relativedelta(seconds=1)) ## Out ## --- 当日: 2022-03-15 17:23:40 1日後: 2022-03-16 17:23:40 1時間後: 2022-03-15 18:23:40 1分後: 2022-03-15 17:24:40 1秒後: 2022-03-15 17:23:41
なお、複数の引数で差分を表現することもできます。
# 複合足し算 print('当日:', day1) print('1日後+1時間後:', day1+ relativedelta(days=1, hours=1)) ## Out ## --- 当日: 2022-03-15 17:23:40 1日後+1時間後: 2022-03-16 18:23:40
datetime型の不等号表現
datetime型は不等号で日時の前後関係が表現できます。
これを利用することで、ある日からある日までのデータを繰り返し処理するといったことができます。
サンプルコードを以下に示します。
start_time = datetime(2022, 3, 25) end_time = datetime(2022, 4, 2) ob_time = start_time while (ob_time <= end_time): print(ob_time) ob_time = ob_time + relativedelta(days=1) ## Out ## --- 2022-03-25 00:00:00 2022-03-26 00:00:00 2022-03-27 00:00:00 2022-03-28 00:00:00 2022-03-29 00:00:00 2022-03-30 00:00:00 2022-03-31 00:00:00 2022-04-01 00:00:00 2022-04-02 00:00:00
datetime型 ←→ 文字列
datetime型 → 文字列
datetime型を所望の文字列に変換するには strftime を使用します。
書式を指定することでその書式の文字列として出力されます。
import datetime
# datetime型 → 文字列 # datetime型 → 文字列 day1 = datetime.datetime(2022, 3, 15, 17, 23, 40) date_str = day1.strftime('%Y/%m/%d %H:%M:%S') date_str2 = day1.strftime('%Y年%m月%d日 %H時%M分%S秒') print(date_str) print(date_str2) ## Out ## --- 2022/03/15 17:23:40 2022年03月15日 17時23分40秒
文字列 → datetime型
特定の文字列をdatetime型にする場合には、strptime を使用します。
文字列の書式をきちんと指定すれば、それをもとにdatetime型として読み取ってくれます。
# 文字列 → datetime型 date_str = '2022/3/15 17:23-40' day2 = datetime.datetime.strptime(date_str, '%Y/%m/%d %H:%M-%S') print(day2) ## Out ## --- 2022-03-15 17:23:40
あとがき
いかがだったでしょうか。
日付に基づいたデータ、処理を扱う場面はたくさんあると思うので、その際は有効活用していきたいです!
【PyTorch】自作のDataset, DataLoader のつくり方!
まえがき
機械学習モデルの検証の際にPyTorchに付属のMNISTなどのデータセットを使用することも多いと思いますが、
実際の現場では独自のデータを使う機会の方が多いと思います。
今回は機械学習フレームワークPyTorchで自作のDataset, DataLoaderのつくり方をご紹介していきます!
Dataset のつくり方
まず必要なライブラリをインポートします。
Dataset, DataLoader はまとめてインポートできます。
import torch from torch.utils.data import Dataset, DataLoader from torchvision import transforms
サンプルデータを作成します。
numpy でデータを扱うことが多いと思うので、numpyで作成します。
import numpy as np sample_data = np.random.rand(100, 32, 32, 3)
sample_data.shape ### ------------------------- (100, 32, 32, 3)
では実際にDatasetを作成しましょう。雛形はこちらです。
class MyDataset(Dataset): def __init__(self, input_data): self.input_data = input_data self.len = input_data.shape[0] def __getitem__(self, index): img = self.input_data[index] return img def __len__(self): return self.len
必要な要素は2つです。
__getitem__(self, index)
①指定されたindexのデータを返すメソットです。
__len__(self)
②データセットの大きさ(長さ)を返すメソットです。
こちらに先ほどのサンプルデータを渡し、データセットを作成します。
dataset = MyDataset(sample_data) print(type(dataset[0])) print(dataset[0].shape) ### ---------------------- <class 'numpy.ndarray'> (32, 32, 3)
ただしこのままだと元のnumpy配列のままのデータセットです。
PyTorchで扱うには、Tensor に直さなくてなならないのでDataset内部でTensorに直す処理を加えましょう。
そのように修正したDatasetがこちらです。
class MyDataset(Dataset): def __init__(self, input_data, transform=None): self.input_data = input_data self.len = input_data.shape[0] self.transform = transform def __getitem__(self, index): img = self.input_data[index] if (self.transform is not None): img = self.transform(img) return img def __len__(self): return self.len
transform = transforms.Compose([transforms.ToTensor()]) dataset = MyDataset(sample_data, transform) print(type(dataset[0])) print(dataset[0].size()) ### ---------------------------- <class 'torch.Tensor'> torch.Size([3, 32, 32])
配列もnumpy(H, W, C) → tensor(C, H, W) にきちんと変換されてますね。
このtransforms.Compose()内にデータセットに加えたい一連の処理を順番に記述できます。
例えば、
transform = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor()])
とすると、
①画像サイズを256に変換
②画像の中心を切り取ってサイズを224にする
③テンソルに変換
というような一連の処理を加えることができます。
どのような処理があるかは他の参考ページをご参照ください。
ちなみに教師あり学習の場合、入力データとその教師ラベルをセットでデータセットにすることが多いと思うのでそのコードも載せておきます。
class MyDataset(Dataset): def __init__(self, input_data, label_data, transform=None): self.input_data = input_data self.label_data = label_data self.len = input_data.shape[0] self.transform = transform def __getitem__(self, index): img = self.input_data[index] label = self.label_data[index] if (self.transform is not None): img = self.transform(img) return img, label def __len__(self): return self.len
transform = transforms.Compose([transforms.ToTensor()]) label_data = np.ones(sample_data.shape[0]) dataset = MyDataset(sample_data, label_data, transform) print(dataset[0][0].size()) print(dataset[0][1]) ### ---------------------------- torch.Size([3, 32, 32]) 1.0
DataLoader のつくり方
Dataset が作成できたので、続けてDataLoaderを作成しましょう。
DataLoader はとても簡単です。
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
batch_size を指定することで、1回のiterateで何個のデータが渡されるかを指定できます。
shuffleはデフォルトはFalseになっており、datasetの順番通りにデータが渡されるのですが、
過学習を防ぎたい場合に訓練データをランダムな順番で渡して欲しい場合もあるので、
その際はshuffle=Trueにしておきましょう。
for img, label in dataloader: print(img.size(), label.size()) ### --------------------------------------- torch.Size([32, 3, 32, 32]) torch.Size([32]) torch.Size([32, 3, 32, 32]) torch.Size([32]) torch.Size([32, 3, 32, 32]) torch.Size([32]) torch.Size([4, 3, 32, 32]) torch.Size([4])
モデルへの入力時のエラー
for img, label in dataloader: img = img.to(device) output = model(img)
というような形でデータローダからモデルへ入力する際に
RuntimeError: expected scalar type Double but found Float
というエラーが出されることがあります。
基本的にモデル内のパラメータの型と入力データの型は一致している必要があります。
この際の解決法は入力データを img.float() として型変換することです。
for img, label in dataloader: img = img.to(device).float() output = model(img)
あとがき
いかがだったでしょうか。
DatasetやDataLoaderは自作でモデル作成をやり始めると必ず通る最初の関門なので、
(モデル作成のメイン部分ではないですし(>_<))簡単にコーディングできるようなっておきたいですね。
【入門/基礎】コンテナとは...?
まえがき
最近システムをサーバレスで作ることが増えてきて、その際にコンテナについて勉強したので共有したいと思います!
コンテナはとてもホットなトピックですし、Googleのサービスも基本的にコンテナ上で動いているということなので、今後はエンジニアとしてより必須知識になっていくでしょう!
参考書
コンテナとは...?
ではコンテナについて説明をしていきます。
まず一般的に「コンテナ」というと、大型の貨物船に載っている貨物を詰め込んだ箱のことを想像される方が多いと思います。
今回扱う「コンテナ」も同様に、サーバ(大型の貨物船)上に、ソフトウェア・プログラムやデータ(貨物)を詰め込んだ箱を載せたものだと思ってください。
コンテナを扱う際にオープンプラットフォーム「Docker」というものを使いますが、このDockerのマークを見ると、鯨さんの上にいくつもの箱が載っていますね。

こんな感じで1つのサーバ上にいくつものコンテナが配置され、動作させることが可能です。
ではどのようなソフトウェア・プログラム・データが1つのコンテナ(箱)に詰め込まれるのでしょうか。基本的には、「1つのコンテナにつき1つのアプリケーション」という考えのもとコンテナは作成されます。そのためアプリケーションを動かすために必要なソフトウェア・プログラム・データなどを1つのコンテナにまとめます。
コンテナの特徴
環境の隔離
前述の通り、コンテナはアプリケーションの動作に必要なものを1つにまとめたものです。
そしてこのコンテナはコンテナごとに隔離された環境を用意できます。そのためそれぞれ隔離された環境でアプリケーションを動作させることができます。

環境が隔離されない場合、どういうことが起こりうるか考えます。
例えば異なるシステムで動作しているプログラムAとプログラムBが同じライブラリ(Ver.3)を使用している場合に、プログラムBの都合によりこのライブラリをVer.5にアップデートした場合に、環境の競合によってプログラムAでこのライブラリが使用できなくなることがあります。
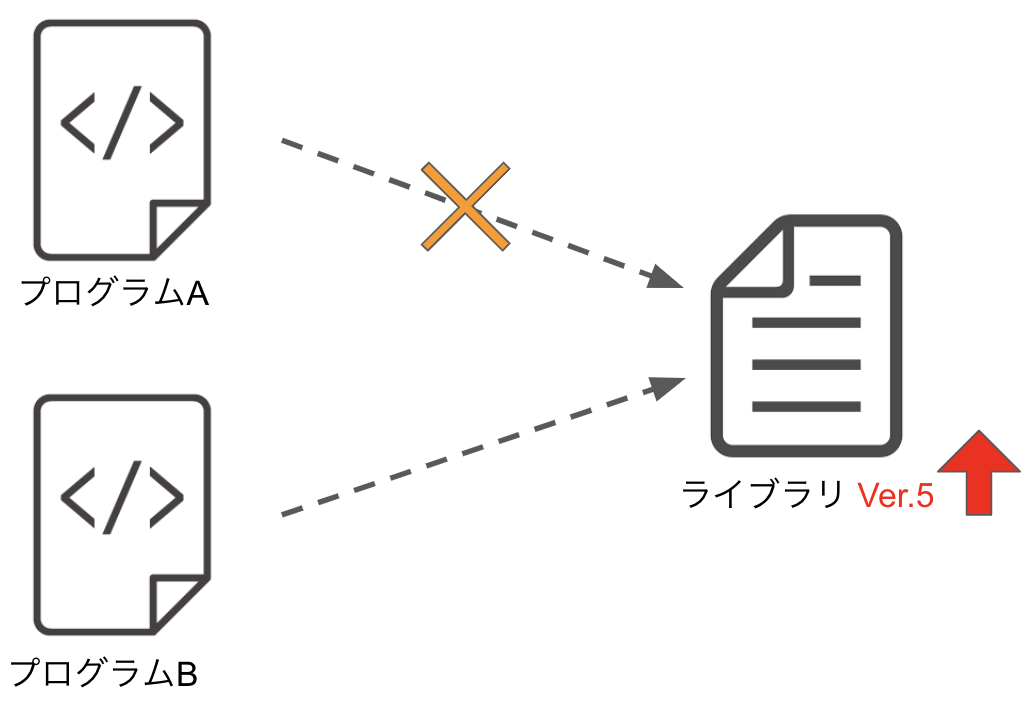
複数のシステムが同居しているとこのようなことが容易に起こりうるため大変不便です。なので実際の業務ではシステムごとにサーバを分けて、システムが同居しないようにしていますが、このようにするとどんどん使用するサーバが増えてしまい、コストや管理負担が増えてしまいます。
一方環境が隔離できる場合
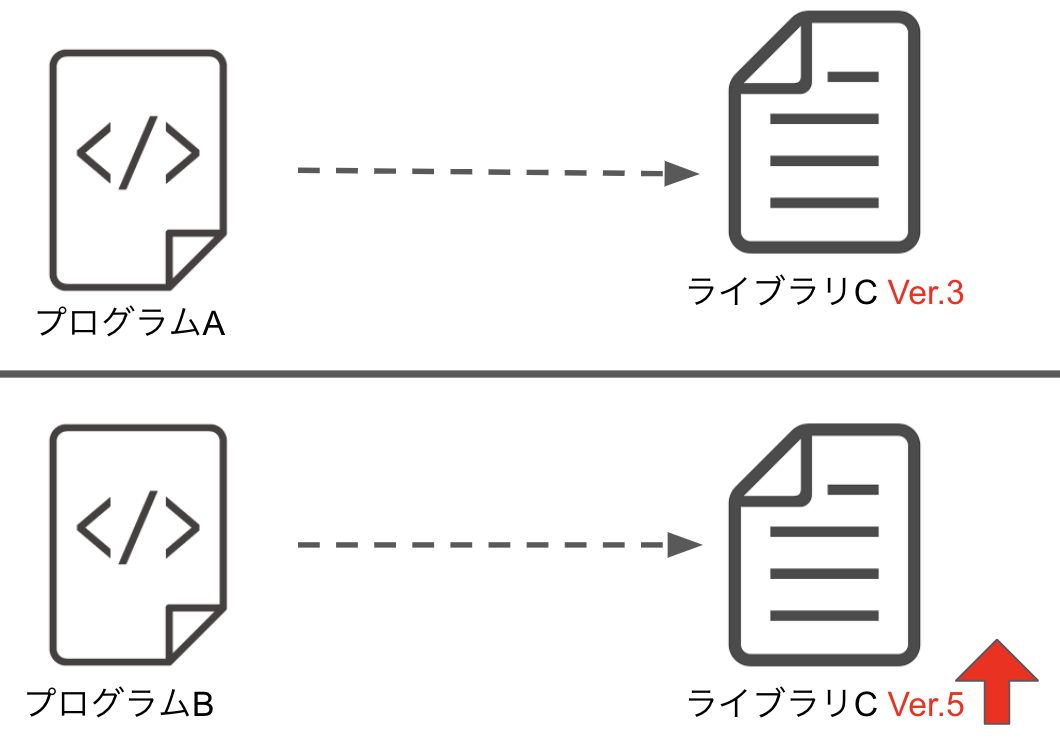
環境の競合が起こらず、同じサーバに複数のシステムが同居していても大丈夫なのです。
持ち運び可能
コンテナは持ち運びが可能です。
コンテナはコンテナイメージというものをもとにして作成されます。このコンテナイメージは他の人と共有ができ、Docker Engine などをインストールさえしていれば、誰でも起動することができるのです。
前述のように、コンテナはアプリケーションの動作に必要なものを1つに詰め込んだものなので、そのコンテナイメージさえ入手できれば、手元のPCでもそのアプリケーションを動作させることができるのです。
そのため、コンテナイメージさえあれば手元のPCをWebサーバ化させたり、DBサーバ化させたりもできます。
また、コンテナイメージはどこかのリポジトリに置いておいて、必要なときにそこから入手するのですが、多くのコンテナイメージが Docker Hub に置いてあります。
Docker Hub には公式のコンテナイメージなども置いてあり、
例えばApacheやMySQLなどの公式が作成したコンテナイメージもあります。
また、公式のコンテナイメージだけでなく自分でカスタムしたコンテナイメージをDocker Hub を通じて世界中の人と共有できますし、他の人が作成したコンテナイメージを使用、または拡張したりもできます。
複数コンテナの同時起動
前述のようにコンテナを使うことで環境を隔離することができるので、複数のコンテナを1つのサーバに安全に同居・起動させることができます。例えば Wordpressを使用したい場合には ApacheとMySQLが必要ですが、コンテナであればこれら2つのコンテナを同時に起動させることで、まるで2つのサーバが独立して稼働しているかのように扱えます。
つまり別々のコンテナを同時に起動させ、組み合わせることで1つのアプリケーションを構築することもできるのです。
Docker にはLinuxが必ず必要
コンテナを扱う際に必要なオープンプラットフォーム「Docker」には必ずLinux OSが必要です。WindowsやMac OSでもDockerを使用することはできますが、どこかしらには必ずLinux OSが組み込まれています。
Docker の仕組み
「Docker」という単語が何度か出てきているのでこちらについても簡単に説明したいと思います。
「Docker」とは、コンテナを扱う際に必要なオープンプラットフォームのことです。
簡単にいうと、Linux OSにDocker EngineをインストールしていればDockerのコマンドを使うことでコンテナに対する処理が行えるようになるということです。
イメージで言うとこんな感じ。

WindowsやMac OSであったとしても内部的に必ずLinux OSを持つようにしてその上でDocker Engineは動いています。
コンテナ内部にディストリビューションが含まれる
コンテナの特徴としてもう1つ、コンテナ内部にディストリビューションを持つという特徴があります。
まずディストリビューションとは何かというと、OSにはハードウェアを操作するための「カーネル」と呼ばれる部分があります。
ただしソフトウェアはこの「カーネル」に直接指示を出すことはできず、「カーネル」がその指示を理解できるよう仲介してくれる「ディストリビューション」というものを通じて「カーネル」に指示を送ったり、「カーネル」からの処理結果を受け取ったりしています。
有名なディストリビューションには、Red HatやCentOS、Ubuntuなどがあります。

コンテナの場合、この「ディストリビューション」をコンテナ内に保持しています。そのため、複数のOSが競合したりせず(コンテナが幾つあろうがカーネルは1つのため)オーバーヘッドが少なく、起動も速いのです。
VMとの比較
コンテナと同じように複数の環境を作成できると言う点でVM(Virtual Machine)がありますが、こちらと比較してみましょう。

VMはコンテナとは異なり、ハイパーバイザを介してハードウェアのリソースを複数のOS環境に分け、それぞれで仮想マシンが稼働しています。
VMの利点としては以下のようなメリットがあるようです。
- 複数のOSでハードウェアリソースを共有
- 物理で可能な機能はほぼ実現可能
- OSを問わず仮想マシンを稼働可能
- 物理と同様にIP管理が可能
VMでは Host OS リソースを使用しながら、 Guest OS の動作を演算し直して動作させているため、コンテナに比べ動作が遅いと言われています。またリソースに無駄が生じやすいとも言われています。
コンテナのメリット・デメリット
改めてコンテナのメリット・デメリットを抑えます。
メリット
- アプリケーションやソフトウェアを環境ごと隔離できる
- アプリケーション・ソフトウェアごとの管理がしやすい
- 他への悪影響を考慮せずにアップデートでき、最新の状態に保てる
- コンテナイメージ化して持ち運び・共有がしやすい
- VMに比べ、起動・動作が速い
- サーバ台数を削減できる
- 開発環境と本番環境の環境の違いによる障害が起こらない
- 個々にコンテナを開発することで、開発者同士で競合しない
デメリット
- 1つのサーバに多数のコンテナを載せる場合、その物理マシン自体に障害が起こった際の影響が大きい
あとがき
いかがだったでしょうか。コンテナについて少しでもご理解いただけたでしょうか。
別の記事でDockerの使い方や、余裕があればKubernetesの使い方なども(Kubernetesは中々まとめるの難しそうですが (>_<))触れていきたいと思います!
numpy配列を効率的に連結させる!
まえがき
データ分析を行なっていると、複数のnumpy配列を特定の軸で連結させたいことはないだろうか。
私もこれまでは、空のnumpy配列を用意してそれにnp.append()などで連結するなどの方法をとっていたのだがとても面倒でした。
今回はより効率的に複数のnumpy配列を連結する方法を紹介していきます!
① リストで連結する
要素の追加や削除が特に大きな制約なく行えるリストはPythonの長所ですよね。
リストの追加には、appendを使います。
list0 = [] list1 = [0, 1, 2] list2 = [3, 4, 5] list0.append(list1) list0.append(list2)
list0 ### ----------------------------------- [[0, 1, 2], [3, 4, 5]]
リストの連結には、extendを使います。
list0 = [] list1 = [0, 1, 2] list2 = [3, 4, 5] list0.extend(list1) list0.extend(list2)
list0 ### ----------------------------------- [0, 1, 2, 3, 4, 5]
では連結させる要素がリストではなく、numpy.array()型だった場合はどうなるであろうか。
list0 = [] arr1 = np.arange(0, 2*2*3).reshape(2, 2, 3) arr2 = np.arange(100, 100+4*2*3).reshape(4, 2, 3) list0.append(arr1) list0.append(arr2) list0 ### ----------------------------------- [array([[[ 0, 1, 2], [ 3, 4, 5]], [[ 6, 7, 8], [ 9, 10, 11]]]), array([[[100, 101, 102], [103, 104, 105]], [[106, 107, 108], [109, 110, 111]], [[112, 113, 114], [115, 116, 117]], [[118, 119, 120], [121, 122, 123]]])]
numpy.array()型の要素がリスト化されるだけである。
問題はextendした場合である。
list0 = [] arr1 = np.arange(0, 2*2*3).reshape(2, 2, 3) arr2 = np.arange(100, 100+4*2*3).reshape(4, 2, 3) list0.extend(arr1) list0.extend(arr2) list0 ### ----------------------------------- [array([[0, 1, 2], [3, 4, 5]]), array([[ 6, 7, 8], [ 9, 10, 11]]), array([[100, 101, 102], [103, 104, 105]]), array([[106, 107, 108], [109, 110, 111]]), array([[112, 113, 114], [115, 116, 117]]), array([[118, 119, 120], [121, 122, 123]])]
なんとnumpy.array()型のaxis=0の方向に連結されるのである...!
print(arr1.shape) print(arr2.shape) print(np.array(list0).shape) ### ----------------------------------- (2, 2, 3) (4, 2, 3) (6, 2, 3)
このやり方の嬉しい点は、形状を定義した空の配列を用意する必要がなく、リストを拡張するだけなので高速に処理を行えるところである。
② 任意の軸でnumpy配列を連結する方法
リストのextendを使ったやり方は、axis=0の軸でしか連結できないがこれを任意の軸で連結させたい場合には、numpy.concatenate()を使用する。
list0 = [] arr1 = np.arange(0, 2*2*3).reshape(2, 2, 3) arr2 = np.arange(100, 100+2*4*3).reshape(2, 4, 3) arr3 = np.arange(200, 200+2*3*3).reshape(2, 3, 3) list0.append(arr1) list0.append(arr2) list0.append(arr3) list0 ### ----------------------------------- [array([[[ 0, 1, 2], [ 3, 4, 5]], [[ 6, 7, 8], [ 9, 10, 11]]]), array([[[100, 101, 102], [103, 104, 105], [106, 107, 108], [109, 110, 111]], [[112, 113, 114], [115, 116, 117], [118, 119, 120], [121, 122, 123]]]), array([[[200, 201, 202], [203, 204, 205], [206, 207, 208]], [[209, 210, 211], [212, 213, 214], [215, 216, 217]]])]
arr1, arr2, arr3 の3つのnumpy配列をaxis=1の軸で連結させたい場合は以下のようにする。
np.concatenate([arr for arr in list0], axis=1) ### ----------------------------------- array([[[ 0, 1, 2], [ 3, 4, 5], [100, 101, 102], [103, 104, 105], [106, 107, 108], [109, 110, 111], [200, 201, 202], [203, 204, 205], [206, 207, 208]], [[ 6, 7, 8], [ 9, 10, 11], [112, 113, 114], [115, 116, 117], [118, 119, 120], [121, 122, 123], [209, 210, 211], [212, 213, 214], [215, 216, 217]]])
pythonの内包表記を利用して、連結する要素のリストをnumpy.concatenate()の引数に渡すことで任意の軸での連結を行なっている。
np.concatenate([arr for arr in list0], axis=1).shape ### ----------------------------------- (2, 9, 3)
③ 新規の軸で連結する
同じ形状のnumpy配列を新たな軸で連結したい場合もあるだろう。その場合は、numpy.stack()を用いる。
list0 = [] arr1 = np.arange(0, 2*2*3).reshape(2, 2, 3) arr2 = np.arange(100, 100+2*2*3).reshape(2, 2, 3) arr3 = np.arange(200, 200+2*2*3).reshape(2, 2, 3) list0.append(arr1) list0.append(arr2) list0.append(arr3) list0 ### ----------------------------------- [array([[[ 0, 1, 2], [ 3, 4, 5]], [[ 6, 7, 8], [ 9, 10, 11]]]), array([[[100, 101, 102], [103, 104, 105]], [[106, 107, 108], [109, 110, 111]]]), array([[[200, 201, 202], [203, 204, 205]], [[206, 207, 208], [209, 210, 211]]])]
np.stack([arr for arr in list0], axis=0) ### ----------------------------------- array([[[[ 0, 1, 2], [ 3, 4, 5]], [[ 6, 7, 8], [ 9, 10, 11]]], [[[100, 101, 102], [103, 104, 105]], [[106, 107, 108], [109, 110, 111]]], [[[200, 201, 202], [203, 204, 205]], [[206, 207, 208], [209, 210, 211]]]])
np.stack([arr for arr in list0], axis=0).shape ### ----------------------------------- (3, 2, 2, 3)
【Python】決定木・ランダムフォレストの実装
今回はPythonを使って、決定木・ランダムフォレストを実装するやり方を紹介します!
まえがき
決定木・ランダムフォレストともにPythonの scikit-learn というライブラリで簡単に実装することができます!
今回は簡単のために、scikit-learn に内包されている iris というデータ(アヤメという花の花弁の長さや広さとそのアヤメの種類のデータ)を用いて実装します。
データ準備
irisのデータを読み込みます。
from sklearn.datasets import load_iris iris = load_iris()
簡単ですね。これでアヤメのデータが読み込まれました。
これを訓練データとテストデータに分割しましょう。
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(iris['data'], iris['target'])
決定木
決定木を実装します。まずは深さに制限を設けずに学習をさせてみましょう。
criterion は枝分割時のデータのばらつき具合を測る指標を指定しています。
ここでは「ジニ不純度」にしています。
from sklearn.tree import DecisionTreeClassifier tree = DecisionTreeClassifier(max_depth=None, criterion='gini') tree.fit(X_train, y_train)
精度を確認します。
print(f'Train Accuracy: {tree.score(X_train, y_train)*100:.1f} %') print(f'Test Accuracy: {tree.score(X_test, y_test)*100:.1f} %')
Train Accuracy: 100.0 % Test Accuracy: 97.4 %
決定木の場合、深さに制限を設けないと訓練データを完全に分類しきるまで枝分かれしてしまうので訓練データでの精度は100%です。
実際に学習された木を可視化してみましょう。
import graphviz from sklearn.tree import export_graphviz dot_data = export_graphviz(tree, out_file=None, impurity=False, filled=True, feature_names=iris.feature_names, class_names=iris.target_names) graph = graphviz.Source(dot_data) graph

ただしこれだと過学習になっている可能性が高いのである程度の深さのところで枝分かれを打ち切るよう設定する必要があります。
木の深さを指定するには、max_depth という引数を使います。
from sklearn.tree import DecisionTreeClassifier tree = DecisionTreeClassifier(max_depth=5, criterion='gini') tree.fit(X_train, y_train) print(f'Train Accuracy: {tree.score(X_train, y_train)*100:.1f} %') print(f'Test Accuracy: {tree.score(X_test, y_test)*100:.1f} %')
Train Accuracy: 99.1 % Test Accuracy: 97.4 %
ちなみに木系の機械学習のメリットは特徴量の寄与率(重要度)を可視化できるところでした。
こちらも scikit-learn のモジュールで簡単に実装できます。
import numpy as np import matplotlib.pyplot as plt plt.style.use('seaborn-darkgrid') n_features = iris['data'].shape[1] plt.title('Feature Importance') plt.bar(range(n_features), tree.feature_importances_, align='center') plt.xticks(range(n_features), iris.feature_names, rotation=90) plt.xlim([-1, X_train.shape[1]]) plt.show()

この場合だと、patal length がほぼほぼアヤメの種類を判断する要因になっていることがわかります。
ランダムフォレスト
ランダムフォレストを実装してみましょう。
ランダムフォレストも決定木同様 scikit-learn で簡単に実装できます。
各引数の意味はこちらです。
- n_estimator: 木の数
- max_features: 1つの木で用いることのできる特徴量の最大数
- max_depth: 各木の最大深さ
- criterion: 枝分割時のデータのばらつき具合を測る指標(ここではジニ不純度を使用)
from sklearn.ensemble import RandomForestClassifier forest = RandomForestClassifier(n_estimators=3, max_features=3, max_depth=4, criterion='gini') forest.fit(X_train, y_train) print(f'Train Accuracy: {forest.score(X_train, y_train)*100:.1f} %') print(f'Test Accuracy: {forest.score(X_test, y_test)*100:.1f} %')
Train Accuracy: 99.1 % Test Accuracy: 100.0 %
決定木の際よりも学習精度が上がっていますね😁
ランダムフォレストでも特徴量の寄与度(重要度)を可視化できます。
import numpy as np import matplotlib.pyplot as plt plt.style.use('seaborn-darkgrid') n_features = iris['data'].shape[1] plt.title('Feature Importance') plt.bar(range(n_features), forest.feature_importances_, align='center') plt.xticks(range(n_features), iris.feature_names, rotation=90) plt.xlim([-1, X_train.shape[1]]) plt.show()

決定木の際よりも重要となる特徴量が増えていますね。
これはランダムフォレストの特徴である「特徴量のランダム性」が効いているということです!
あとがき
いかがだったでしょうか?
決定木もランダムフォレストも scikit-learn を用いることで簡単に実装することができました。
これらは機械学習の手法の中でも、ユーザー側にとって中身が理解しやすい手法の1つなので、いろんなところで活用できそうです😁
【入門】DecisionTree・RandomForest の基本
概要
最近の機械学習コンペではもっぱらXGBoostやLightGBMが使われることが多いみたいなので、
今回はその基本となる DecisionTree や RandomForest をまとめていきます!
参考書籍
以下の書籍を参考にさせていただきました!
DecisionTree (決定木)
まずは、DecisionTree (決定木) からご説明します。
決定木は対象物を正しいカテゴリに分類するために使用されます。

上の図を見てください。
決定木はノード(節)& それをつなぐエッジ(枝)から構成されます。
この図だとノードは四角のボックスです。
ノードには分類をする際の条件がそれぞれ設定されています。
その条件の判定によってエッジで繋がれた次の(1つ下の階層の)ノードへと移動することになります。
図の中で1番上のノードを「根ノード」、1番下のノードを「葉ノード」といいます。
根ノードから始めて、条件判定を繰り返しながら葉ノードまで到達したら終了です。
つまり葉ノードが最終的なクラスとなります。
この根から枝分かれしていって、最終的な葉に至る様子から「決定木」と呼ばれます。
通常の木とは逆向きですが...
例えばこの図の決定木で「ヒト」がどの動物の種類に分類されるかを見てみましょう。
根ノードから始めて、「肺呼吸である」(Yes)→「恒温動物である」(Yes)→「哺乳類」となり、「ヒト」は「哺乳類」に分類されることがわかります。
決定木の特徴
- 分割条件は分割後の各ノードに含まれるデータのばらつきが最小になるように決められる
- 葉ノードに含まれるデータが全て同じクラスになるまで分割を繰り返す
決定木にはこのような特徴があるため、訓練データでの精度は必ず100%になります。
これは過学習の原因となるため、ある程度の深さで分割を中断させるようにします。
データのばらつき...?
データのばらつきとはいっても、どうやって計算するか気になりますよね。
データのばらつきを定量的に表現する2つの方法をご紹介します。
ここでとは、あるノード
でクラス
に属するサンプル数の割合。
は総クラス数。
不純度は0に近いほどばらつきが少ないです。
回帰の場合
クラス分類を例にして決定木の説明をしてきたが、回帰の場合はどうなるのでしょうか。
クラス分類では、葉ノードのクラスはその葉クラスに属するサンプルの最頻クラスです。回帰の場合、葉ノードの値は葉ノードに属するサンプルの平均値となります。
また分割条件はサンプルの分散が最小になるように分割します。
決定木のメリット・デメリット
メリット
- 分類・回帰の両方に利用できる
- データの正規化などの前処理が必要ない(分割条件はその変数の尺度で表現できる)
- 木を可視化することで分割の処理内容を理解できる
- 特徴量の寄与度(重要度)を計算できる
デメリット
- 表現能力が葉ノードの数(高々ある程度の数までしかない)などに依存しているので、他の手法に比べ学習能力に限界がある
RandomForest (ランダムフォレスト)
決定木でも分類や回帰を行うことは可能ですが、これを使っている人はあまり見受けられない。木系の機械学習手法を使うのであれば RandomForest (ランダムフォレスト)を使うことの方が多いでしょう。
決定木のメリットを活かしつつ、学習能力を向上させることができます!
アンサンブル手法
RandomForestではアンサンブル手法が用いられています。
アンサンブル手法とは、複数のモデルを組み合わせる手法です。
複数の決定「木」を組み合わせていることから、Random"Forest" と呼ばれているのですね。
アンサンブル手法では1つ1つのモデルはそこまで性能は良くありませんが(弱識別器といいます)、複数組み合わせることで性能を良くしています。
アンサンブル手法にはいくつか種類がありますが、ここでは2つ紹介します!
バギング
RandomForestで用いられているアンサンブル手法です。
バギングでは複数あるモデルを並列的に並べ、それぞれのモデルが出した予測結果をもとに多数決を取ることで最終的な予測結果とするようなやり方です。

ブースティング
ブーステイングは複数あるモデルを直列的に並べ、直前のモデルの出力と正解ラベルとの誤差を埋めるように学習を重ねていく手法です。
先に話題に挙げたXGBoostなどはこのブースティングの手法の一種です。

ランダム...?
RandomForest のランダムとは何のことでしょうか?
RandomForest には主に2つのランダム性があります。
データのランダム性
学習に使用するデータを全データからランダムに抽出することで、決定木ごとに学習するデータが異なるようにします。このときの抽出方法は重複を許します。(復元抽出)
この操作によって作成されたデータセットをブートストラップ標本といいます。
分割条件に使用できる特徴量のランダム性
分割条件にもランダム性があります。
決定木では「すべての特徴量」から最善の分割条件を選んでいましたが、
RandomForest ではランダムに抽出した「一部の特徴量」からしか分割条件を選択できません。このときの一部の特徴量の抽出方法は重複を許さないようにします。(非復元抽出)
多重共線性
RandomForestを使用していく際に注意しないといけないのが「多重共線性」です。
「多重共線性」とは特徴量どうしで相関の強いペアが存在していることです。
上でご紹介した参考書籍によれば、相関値が0.95以上が目安だそうです。
なぜ相関が強い特徴のペアが存在するとマズイのかというと、寄与度(重要度)の計算の際なんかに相関のあるペアどうしで寄与度が分散してしまって、正確な値がわからなくなるからだそうです。
回帰問題においても「多重共線性」は問題になる場合があり、例えば相関が強い特徴量ペアがあるとそれらの回帰係数の分散が大きくなり、学習が安定しなくなります。
そのため機械学習においては相関の強い特徴量ペアが見つかった場合は、どちらかの特徴量を消す必要があるのです。
あとがき
今回は DecisionTree と RandomForest について基本的な概念や特徴を中心にご紹介しました。scikit-learn などを使った実際のソースコードは別の記事で書いていきたいと思います!